



























En la web podremos configurar hasta 20 «checks» de forma completamente gratuita, si quieres añadir más tendrás que adquirir la versión de pago. Cada «check» puede significar que esté levantado un servidor u ordenador, o bien que se ha ejecutado correctamente un servicio en concreto. Como veréis más adelante, cada check se puede configurar para avisarnos de que hay un problema, e incluso se puede ajustar el periodo de recepción del check y también el periodo de gracia, para adaptarlo a nuestras necesidades. Este software tiene un total de cuatro estados: pausado (no se ha recibido nunca ningún check o bien lo hemos pausado nosotros), correcto (se ha recibido la solicitud HTTP en tiempo), tarde (no se ha recibido la solicitud HTTP en tiempo y estamos esperando al tiempo de gracia para notificar), caído (se ha superado el tiempo del periodo configurado más el tiempo de gracia). En el estado de caído es cuando se enviará una notificación por diferentes métodos.
Healthchecks soporta una gran cantidad de métodos para notificar las caídas, podemos enviar las notificaciones por email, usando webhooks, por Slack, Gotify, Microsoft Teams, Telegram y muchos más, perfecto para adaptarse perfectamente a nuestro sistema de monitorización actual donde enviarnos los mensajes.

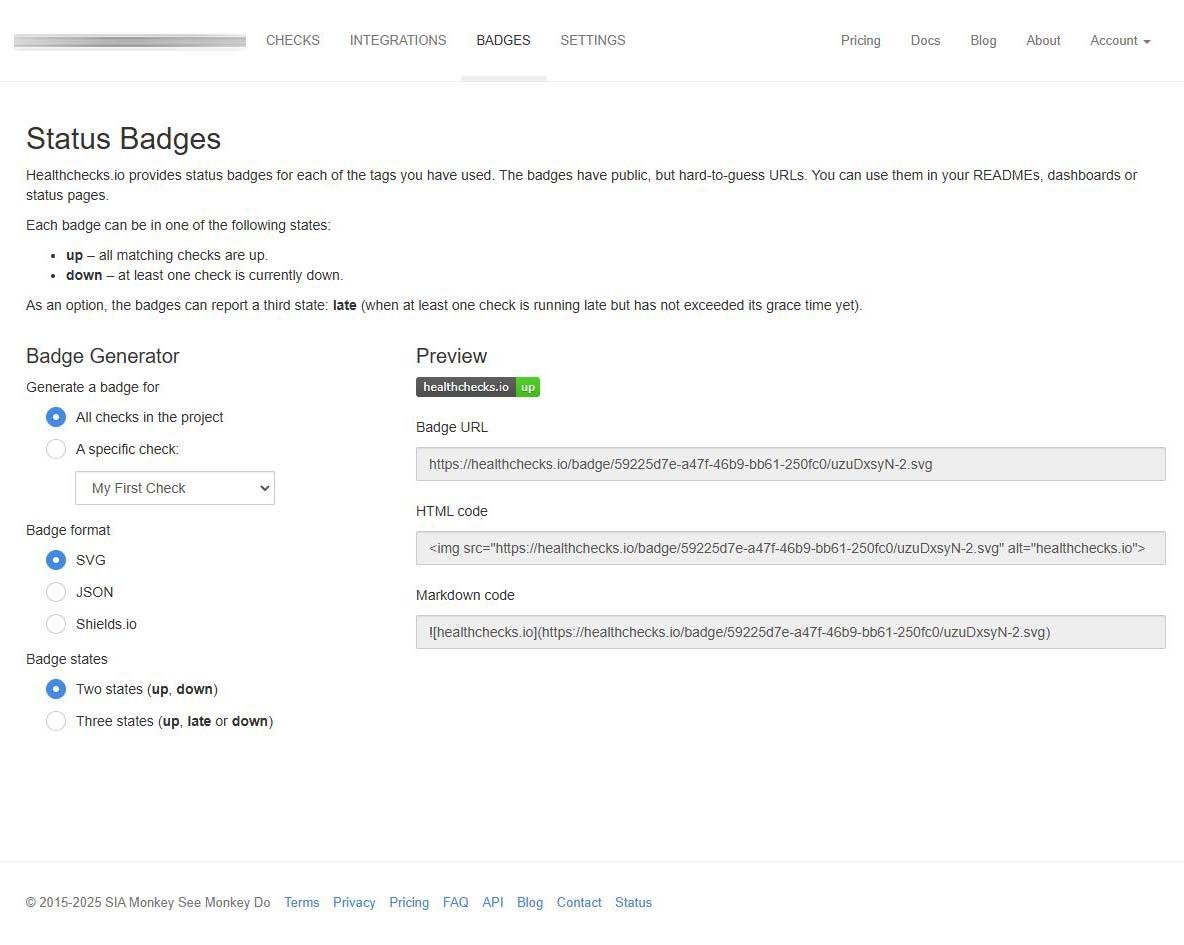
Otras características de este servicio, es que nos proporcionará el código HTTP necesario para realizar los checks en diferentes lenguajes de programación, también podemos ver en detalle un histórico con todas las caídas que hemos tenido (100 entradas por cada check que configuremos en la versión gratis), así como también la posibilidad de crear un distintivo de estado en público, para así añadirlo a una web central de gestión de monitorización. Aunque estos distintivos tienen URL públicas, lo cierto es que están generadas de forma aleatoria y son muy complicadas de adivinar.
Este servicio es perfecto para introducir una solicitud de HTTP en nuestros trabajos de copias de seguridad, emails con informes diarios, renovaciones de certificados SSL, trabajos de importación y sincronización de archivos, así como escaneo de antivirus y también actualizaciones de los DNS dinámicos. Por supuesto, es necesario incorporar la solicitud HTTP en los diferentes scripts que tengamos. También podríamos crear scripts específicos que se encarguen de monitorizar un contenedor Docker en concreto, una aplicación, el retraso a la hora de replicar una base de datos, e incluso comprobar recursos del sistema. Por último, también nos permitirá enviar un simple «ping» desde un servidor o NAS domésticos.
Opciones en el panel de control
Registrarnos en este servicio es realmente fácil, simplemente tenemos que poner nuestro correo electrónico y pinchar en el botón de «Email me a link«. Recibiremos un correo electrónico con un enlace, al pinchar sobre él ya podremos acceder a la web de administración, sin necesidad de crear ningún tipo de credencial de acceso. Además, al introducir este email también se creará automáticamente la integración de «email» para que todos los avisos de los checks nos los envíen a esta cuenta de correo, sin necesidad de configurarlo desde cero.
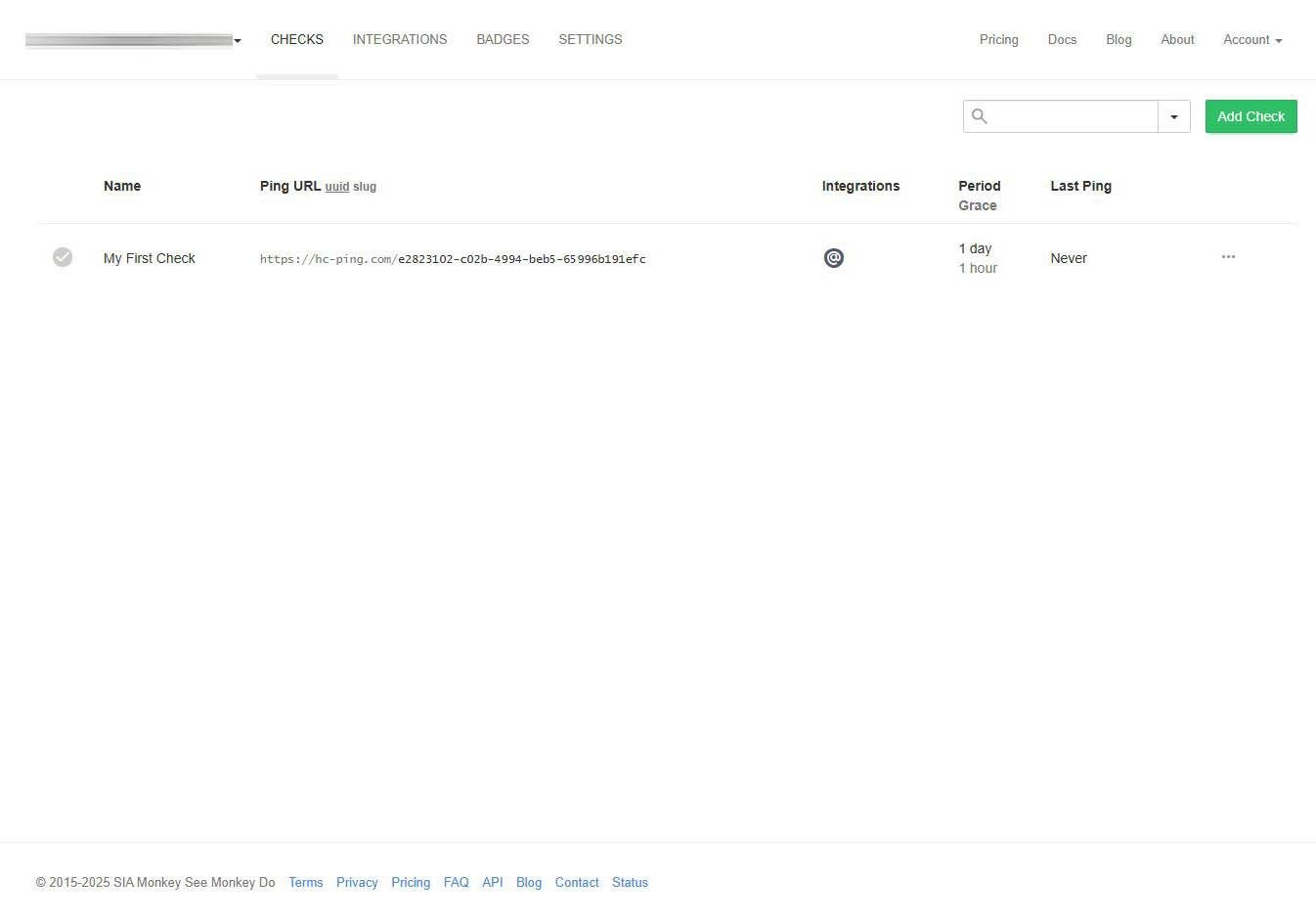
En el menú principal podemos ver «My first Check», con la correspondiente URL a la que tendremos que hacer «ping» mediante una solicitud HTTPS. También podemos ver la integración configurada para los avisos (por email), el periodo de recepción de los checks (un día) y el periodo de gracia (1 hora por defecto). También nos informará sobre la última vez que se ha recibido una comunicación.
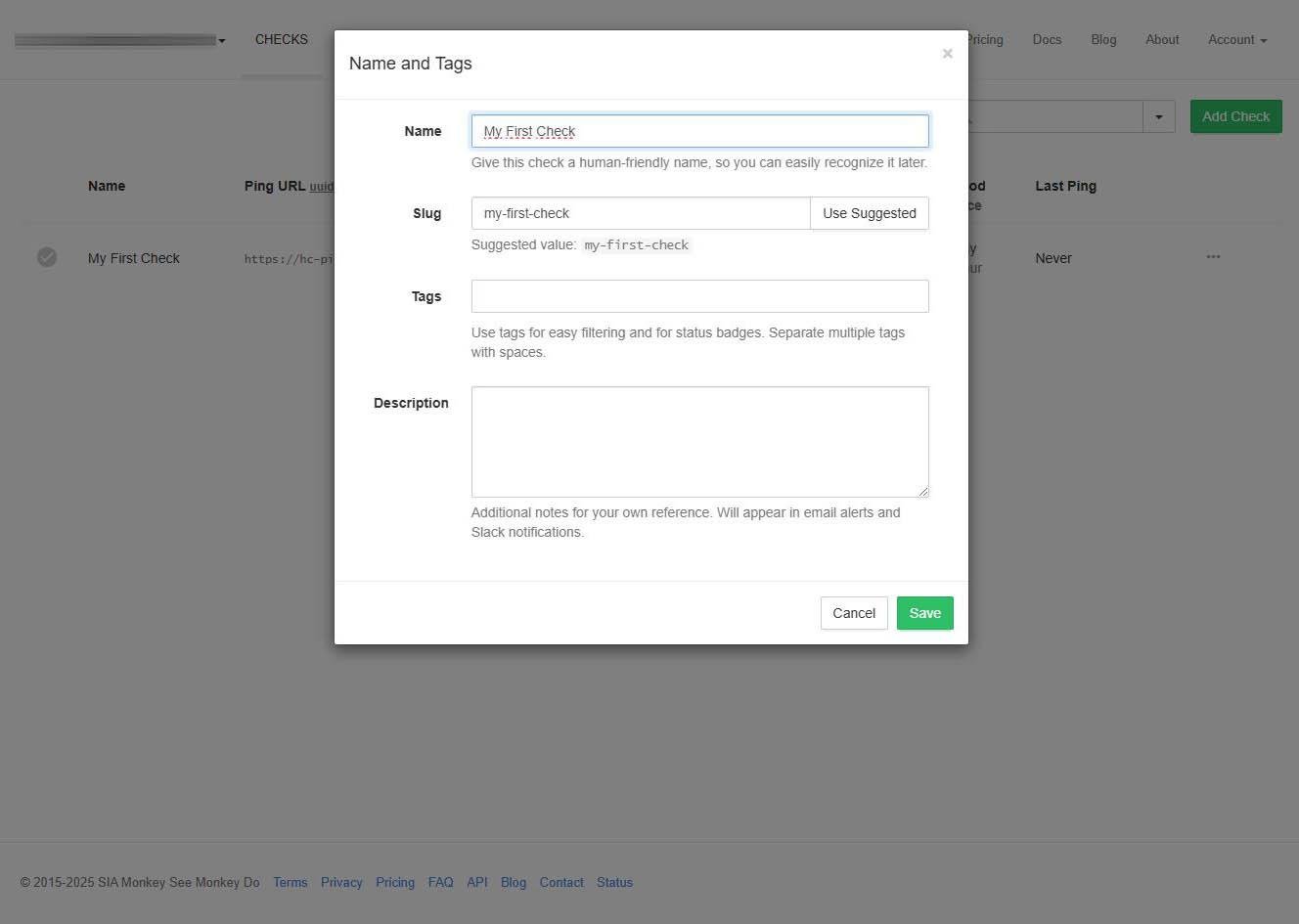
Si queremos editar este «check» que tenemos creado de forma predeterminada, podemos hacerlo sin ningún problema. Podemos configurar el nombre, el slug, incorporar diferentes etiquetas y también poner una descripción, para tener todo muy bien organizado.
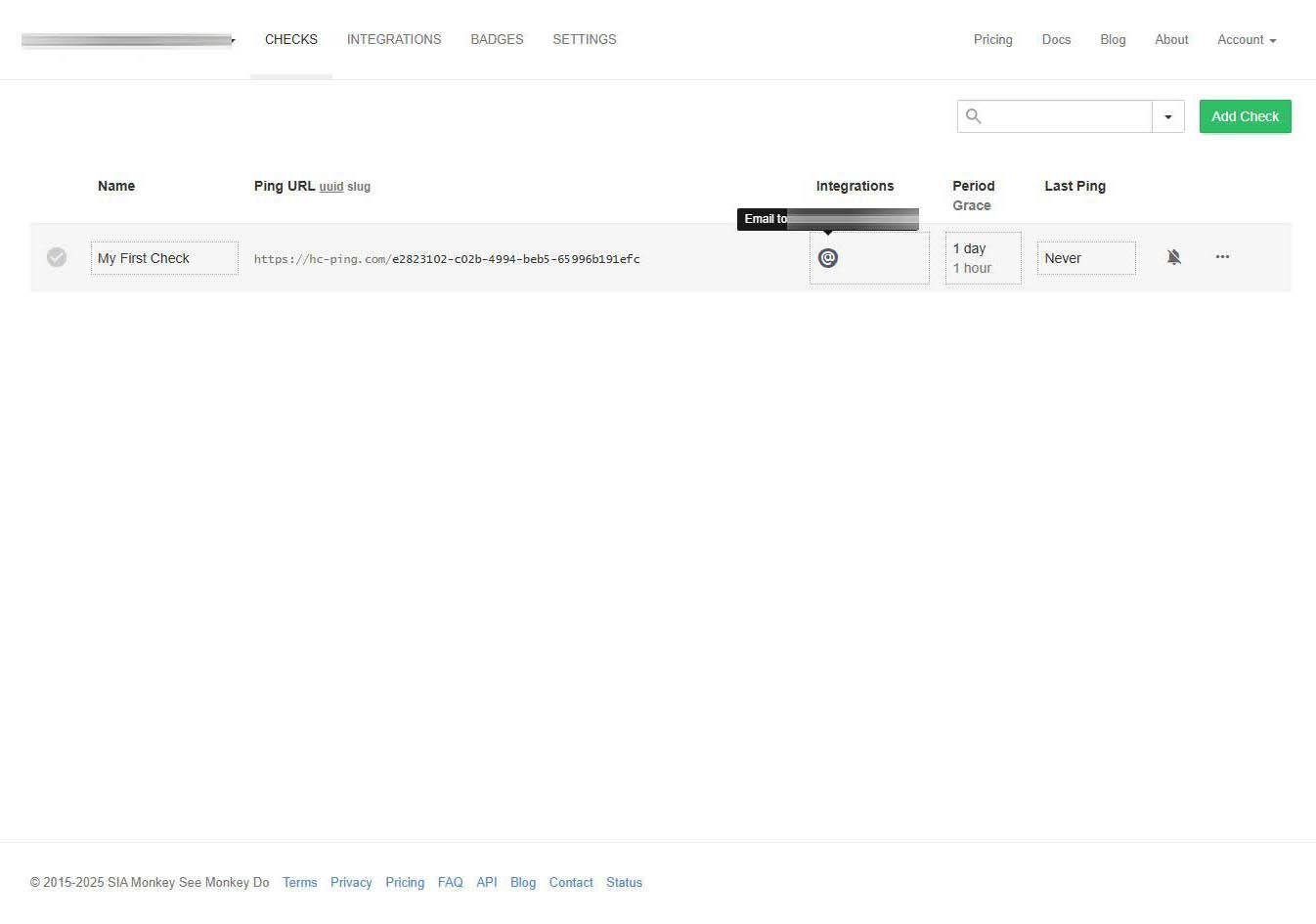
En la sección de «Integrations» podemos ver que tenemos configurado el correo electrónico, así que todas las notificaciones nos llegarán directamente aquí. También podemos editar en cualquier momento el periodo y tiempo de gracia.
En cuanto al tiempo de gracia, como mínimo es de 1 minuto y como máximo de 1 año, además, el tiempo de gracia es también exactamente lo mismo. Hay que tener muy claro qué significa el periodo y el tiempo de gracia:
- Period: es el tiempo entre diferentes solicitudes HTTPS o «pings» que nosotros tenemos configurado. Imaginemos que en el servidor ponemos un cron que envía cada minuto una solicitud HTTPS, lo normal es que configuremos un periodo de 2 minutos para permitir la pérdida de uno.
- Tiempo de gracia: una vez que se ha pasado el periodo y no hemos recibido nada, el tiempo de espera hasta que nos envíe una notificación porque algo está fallando. Lo habitual en el ejemplo anterior es poner 1 minuto.
Con este ejemplo, si en 3 minutos no se ha detectado un «check», se enviará una notificación automáticamente indicando que el servicio se ha caído.
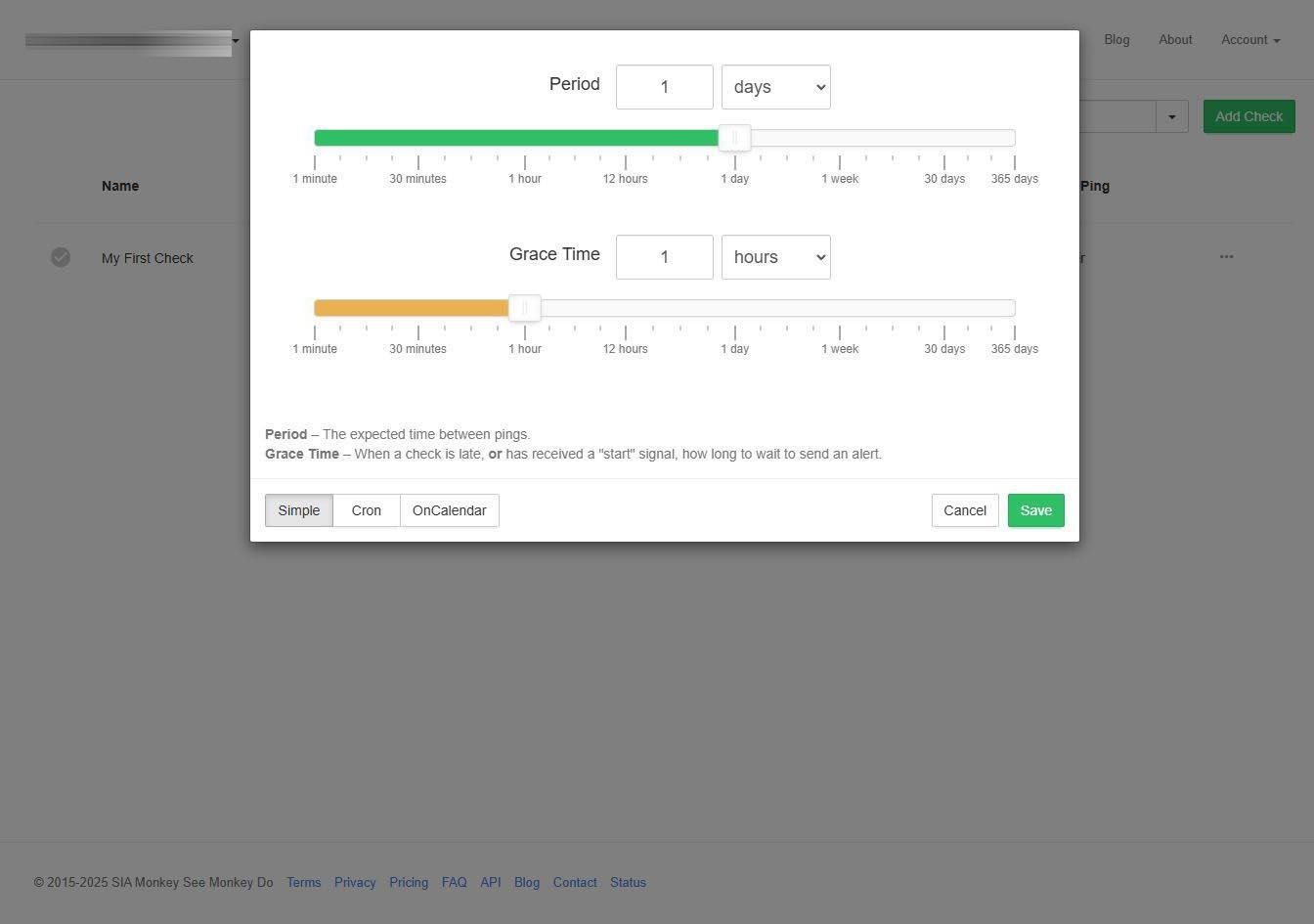
El propio servicio nos permitirá configurar el servicio de cron para posteriormente ponerlo en nuestro sistema operativo, para que así lo tengamos todo realmente fácil y simplemente tengamos que hacer copiar y pegar. Aquí nos indicará cuándo espera que tengamos un check en el servicio.
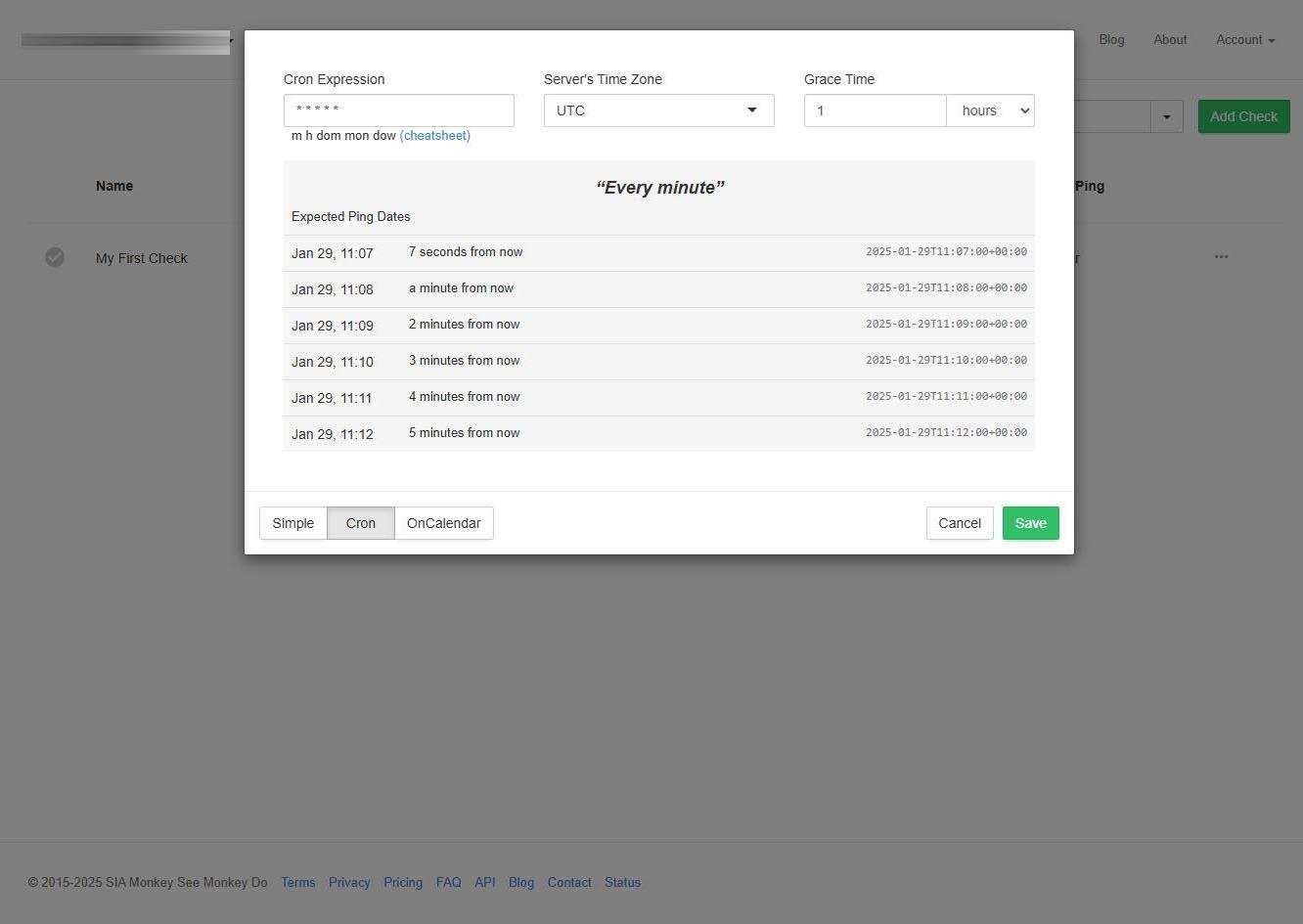
También podríamos crear una expresión de tipo «OnCalendar» para facilitar el envío de los checks en los diferentes procesos o servicios del sistema operativo basado en Linux.
En cualquier momento podemos pausar el «check» por si no lo vamos a usar en una temporada. De forma predeterminada, cuando creamos un check nuevo, estará pausado a la espera de recibir el primer ping desde el servicio o servidor.
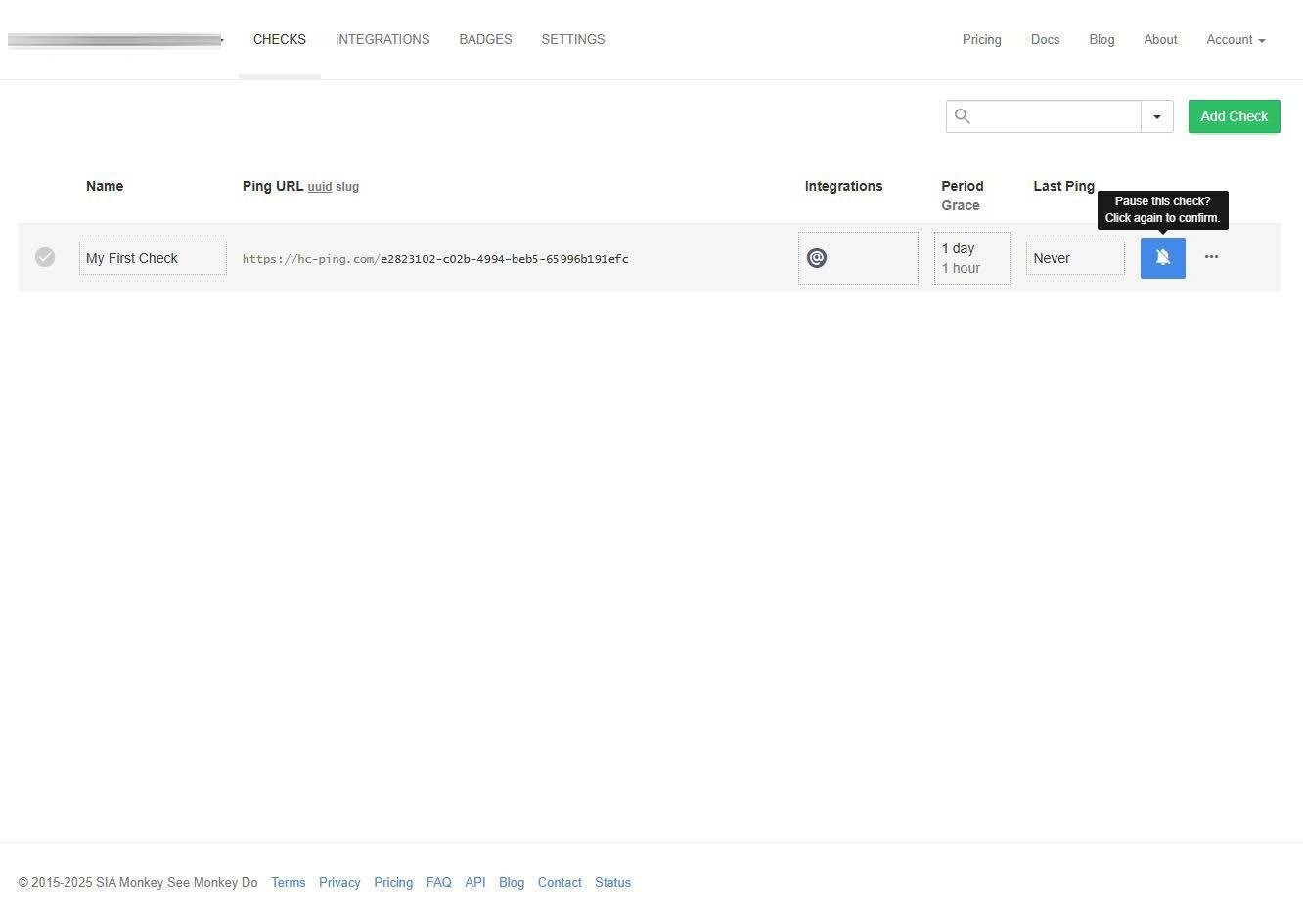
En el menú de administración del «My first check» es donde podemos configurar y editar absolutamente todo lo que queramos, excepto la dirección URL que genera el propio servicio. Aquí podéis ver el estado actual del check, la programación establecida de periodo y tiempo de gracia, métodos de notificación, si queremos copiar el check para reusarlo en otro, eliminarlo, e incluso podemos ver el histórico de eventos. También podemos configurar qué tipo de solicitud HTTP podemos usar, lo habitual es usar todas (HEAD, GET, POST, PUT).
Healthchecks no solamente permite hacer los checks a través de solicitudes HTTPS, sino que también permite hacer esto a través de correo electrónico. Si automatizamos el envío de un correo electrónico a la dirección que nos indica el servicio, podemos hacer este «check» sin necesidad de añadir la orden con cURL o similares. En este caso, el servicio nos permitirá configurar también filtros para los emails que podemos recibir. Hay muchos softwares que nos permiten enviar un correo electrónico cuando no termina bien la tarea, si se ha parado por algún problema o si se ha terminado correctamente. Si ponemos como destinatario este servicio, estaremos centralizando la recepción de todo esto en un único sitio.
Healthchecks también nos proporcionará el código necesario para hacer las solicitudes HTTPS, tenemos ejemplos para configurarlo en Crontab, en scripts usando bash, Python, Ruby, Node.js, Go, PHP, C#, a través del navegador, PowerShell y también el email. La verdad es que esto nos facilitará muchísimo la configuración, porque simplemente tendremos que copiar y pegar la orden, no tenemos que hacerla nosotros mismos desde cero.
Respecto a los servicios para enviar las notificaciones, lo cierto es que es realmente completo porque tenemos mucha variedad, estamos seguros que ya usas alguna de estas herramientas para las notificaciones. A continuación, tenéis un listado de todo lo que soporta:
- Email.
- Webhook
- Discord
- Gotify
- Group (permite enviar a varios a la vez)
- Matrix
- Mattermost
- Microsoft Teams
- Ntfy
- Opsgenle
- PagerDuty
- PagerTree
- Phone Call
- Prometheus
- Pushbullet
- Pushover
- Rocket.Chat
- Signal
- Slack
- SMS
- Spike.sh
- Telegram
- Trello
- Splunk On-Call
- Zulip.
Respecto a las «insignas» de estado, podemos realizar ciertas configuraciones, esto es perfecto para ponerlo directamente en nuestro panel de administración y así podemos ver de forma centralizada todo lo que está ocurriendo. Hay que tener en cuenta que estas insignias son públicas, pero han generado la URL de forma aleatoria y será complicado que alguien pueda llegar «probando». Además, solamente podemos ver el estado del check nada más.
En cualquier momento podremos cambiar el nombre del proyecto de monitorización, también podemos configurar las claves API para acceder a través de esto de forma avanzada. Lo normal será que no lo necesites a nivel doméstico, pero si adquieres la versión de pago y quieres crear nuevos checks de forma rápida, puedes usar la propia API que nos proporciona para automatizar esto.
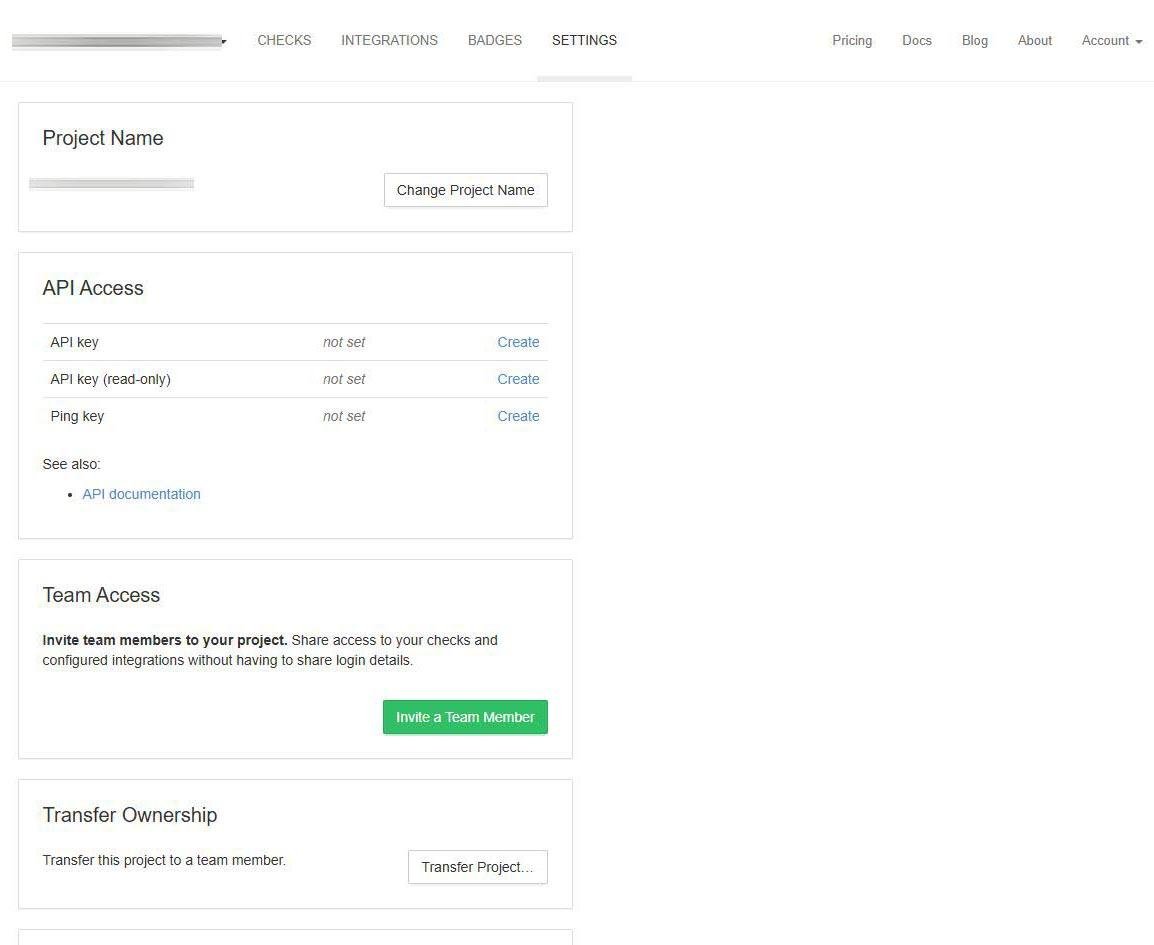
Tenemos la posibilidad de crear diferentes proyectos, por ejemplo, para diferentes localizaciones o varios servidores etc. Lo importante es que tengas todo el sistema de monitorización bien organizado.

Ahora que ya os hemos enseñado todas las opciones y posibilidades de este servicio tan interesante, os vamos a enseñar cómo monitorizar cualquier equipo a modo de «estoy vivo», es decir, que cada cierto tiempo envíe un check indicando que el PC está levantado.
Monitorización de cualquier equipo
En este ejemplo lo único que hemos hecho es coger el código PowerShell que nos proporciona el propio servicio, hemos abierto una consola en PowerShell, y hemos ejecutado el comando que nos proporciona. Automáticamente el servicio detectará que hemos enviado un HTTPS GET tal y como podéis ver. Junto con la solicitud HTTPS GET, aparecerá la dirección IP pública, y también el sistema operativo desde donde lo hemos hecho.
Si pinchamos en el botón de «Ping Now«, lo que hace es enviar un HTTPS POST desde el propio navegador donde lo estamos ejecutando, para comprobar que funciona correctamente. Lógicamente si lo pruebas desde un móvil, te aparecerá otra dirección IP pública diferente como origen, es algo que debes tener en cuenta.
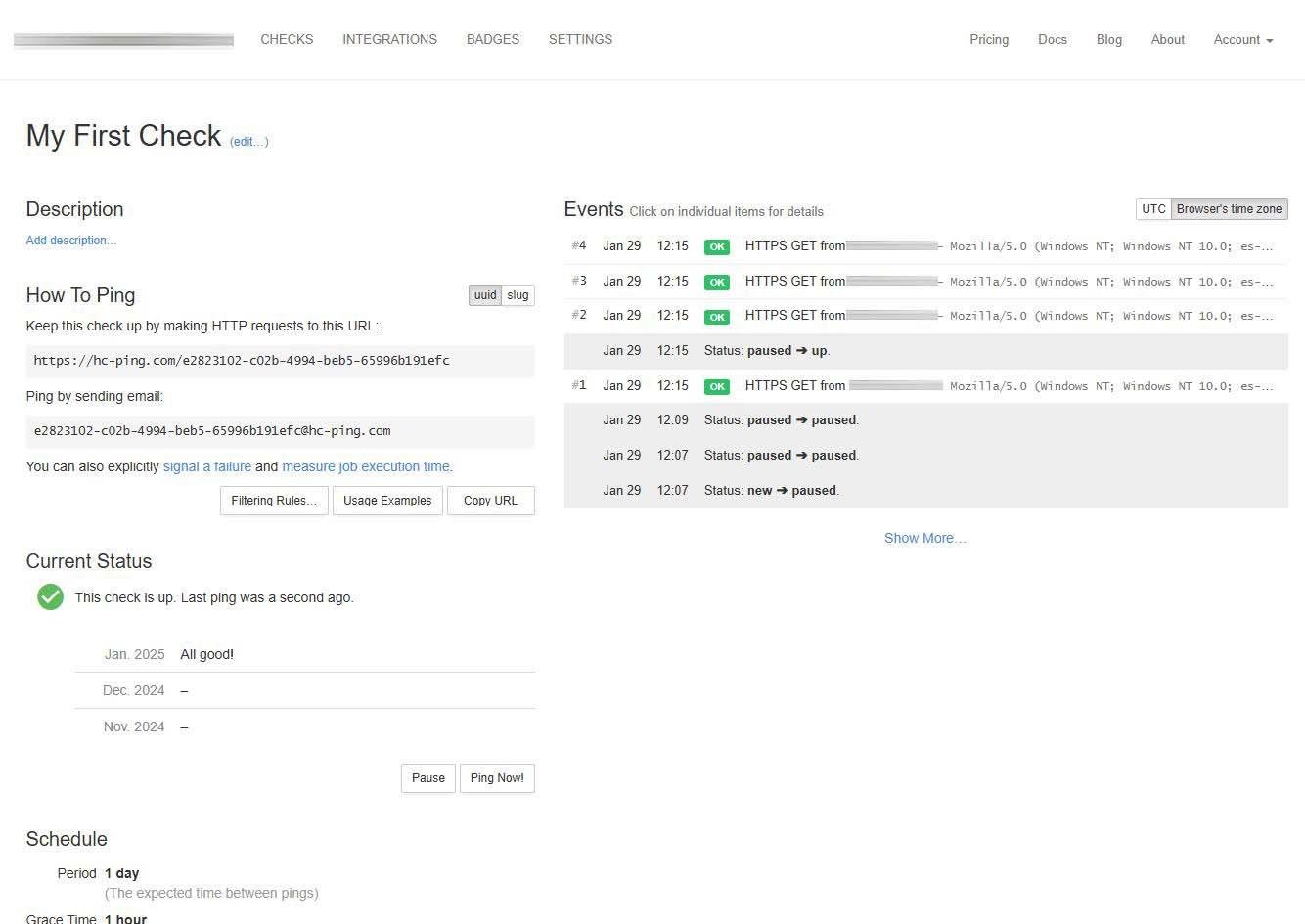
Si pasa el periodo configurado previamente (hemos puesto 1 minuto), nos aparecerá en amarillo a modo de aviso, pero todavía no nos va a notificar porque no hemos pasado por el tiempo de gracia.
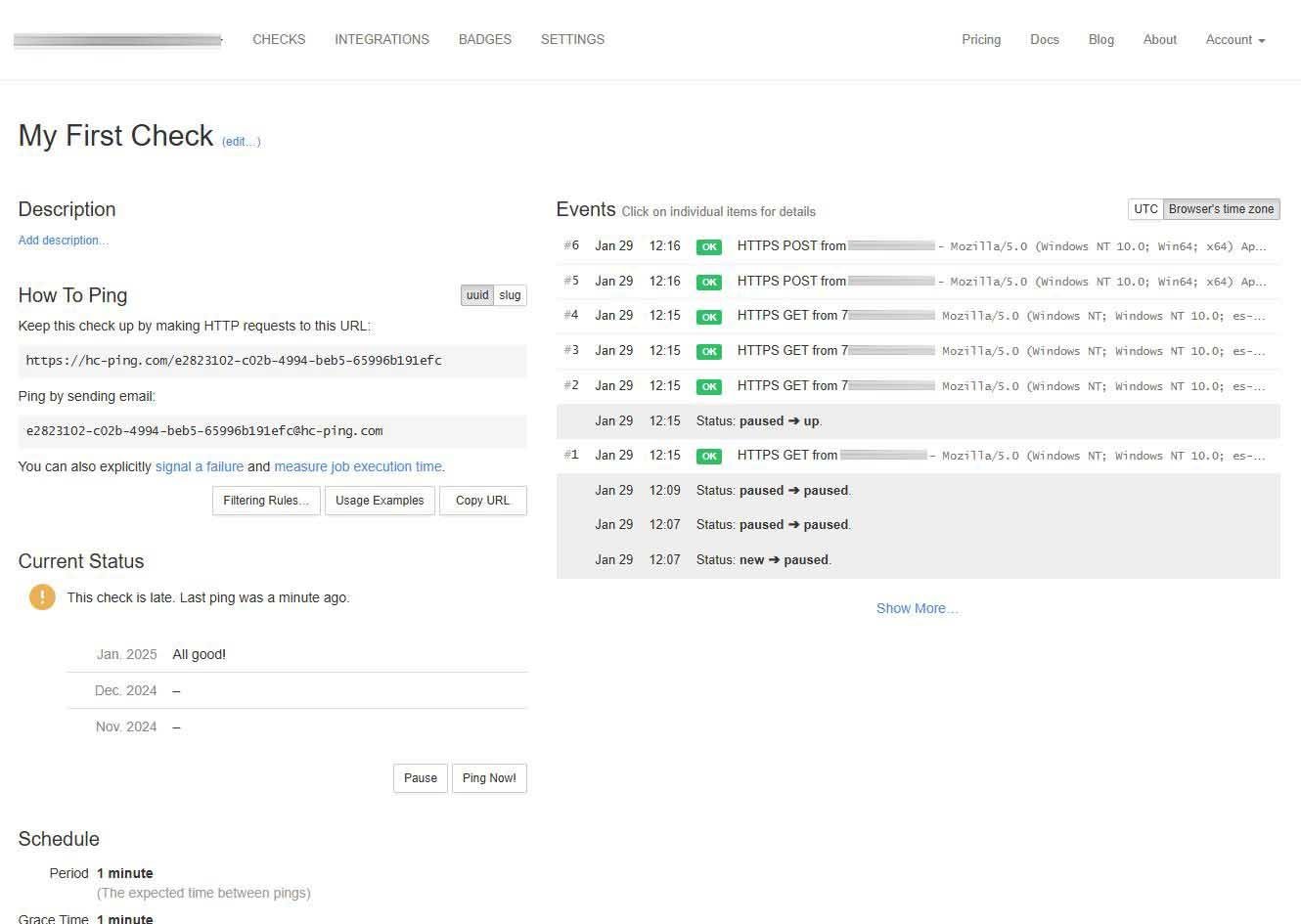
Una vez que haya pasado un minuto de tiempo de gracia, nos aparecerá que el «check» está caído, y es aquí cuando sí nos notificará, concretamente a través de correo electrónico.

En la siguiente captura podéis ver perfectamente el check que no se ha recibido, nos avisará de que existe algún tipo de problema con él.
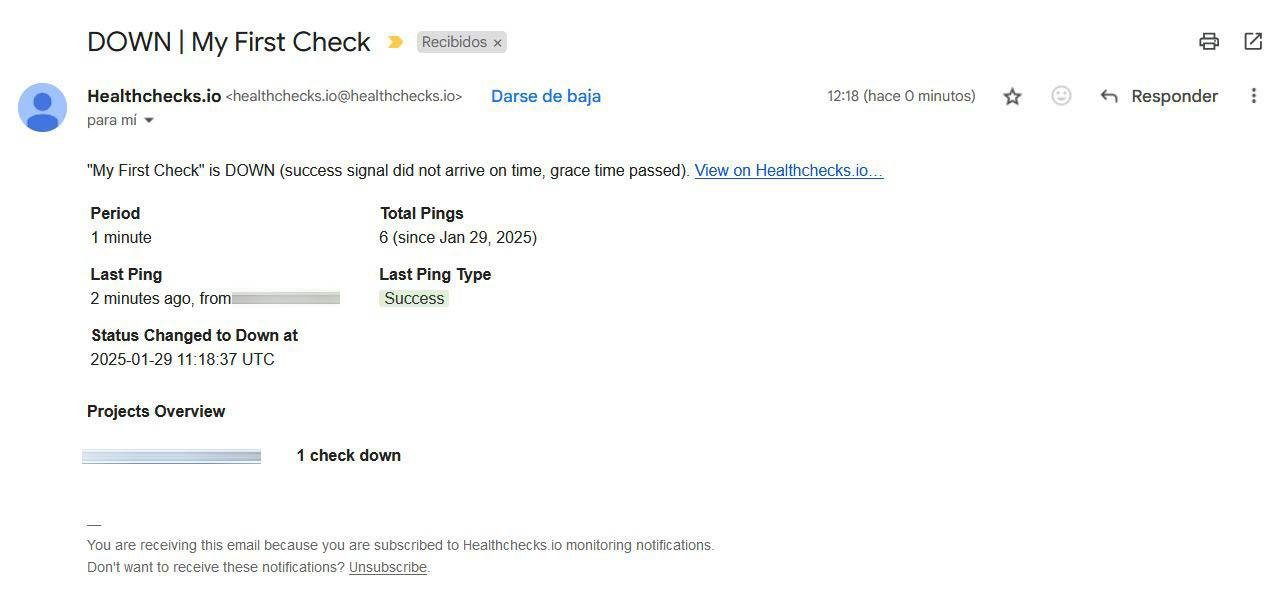
Tal y como podéis ver, este servicio de Healthchecks es realmente interesante, porque nos permitirá no tener que abrir ningún puerto, ya que los checks funcionarán a través de HTTP GET desde el interior de la red local hasta Internet y no al revés. Esta alternativa a Uptime-Robot o a Uptime-Kuma es muy interesante para los casos donde no queramos abrir puertos, ni siquiera a ciertas direcciones IP públicas, para así tener la máxima seguridad posible.












{kind=link}